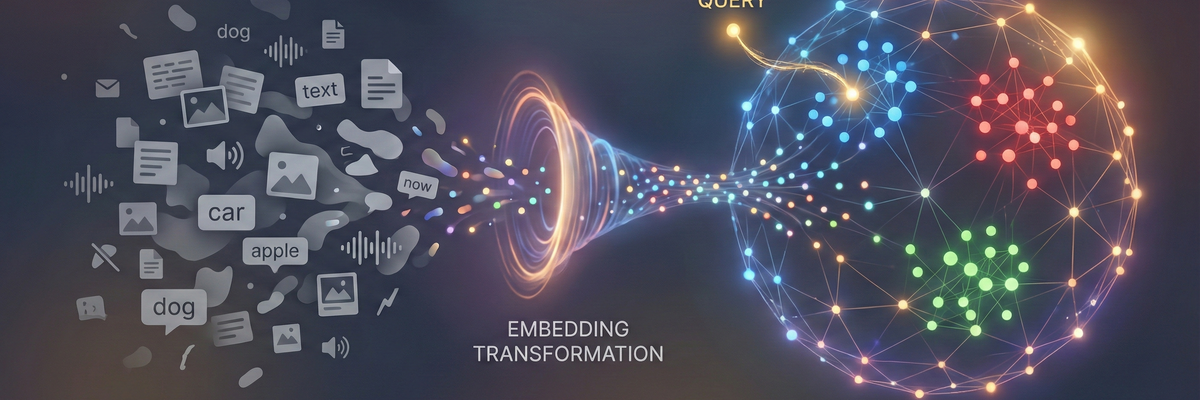
Here is a detailed breakdown of how it works, the retrieval process and the differences to traditional systems.
1. the core concept: embeddings
To understand how a vector database works, you first need to understand what it actually stores. It does not store raw data (such as the text "apple"), but a list of floating point numbers that represent this text.
- The vector: A vector is a series of numbers, e.g. [0.12, -0.45, 0.88, ...].
- The vector space: Imagine a coordinate system. A 2D vector is a point on a piece of paper. However, a vector in a modern database often has 768, 1536 or more dimensions.
- Semantic proximity: In this high-dimensional space, things that have a similar meaning are spatially close to each other. "Dog" and "cat" are close to each other (both pets). "Dog" and "microwave" are far apart.
2 The retrieval process in detail
The process of how a vector database finds an answer differs fundamentally from an SQL query. It takes place in three main phases:
Phase 1: Vectorization (encoding)
When a user makes a search query (e.g. "Which animals live in water?"), this query is not sent directly to the database.
- The text query is sent to the same embedding model (an AI model, e.g. from OpenAI or HuggingFace) that created the data in the database.
- The model converts the question into a vector (query vector).
Phase 2: Mathematical similarity calculation
The database must now calculate which stored vectors are "closest" to the query vector. To do this, it uses mathematical distance measures:
- Cosine Similarity: Measures the angle between two vectors. An angle of 0 degrees means identity (value 1), 180 degrees means the opposite (value -1). This is the standard for text models, as the direction (meaning) is more important than the length (number of words) of the vector.
- Euclidean distance (L2): Measures the direct line of sight between two points.
- Dot Product (scalar product): Measures how much two vectors point in the same direction and takes into account their length.
Phase 3: The search algorithm (ANN vs. k-NN)
This is where the real magic of the vector database lies.
- k-NN (k-Nearest Neighbors): This is the "brute force" method. The database compares the query vector with every single vector in the database. This is extremely precise, but far too slow with millions of data records.
- ANN (Approximate Nearest Neighbors): Vector databases use ANN algorithms instead. They accept a minimal loss of accuracy for a massive increase in speed.
How ANN works (example HNSW):
Currently, the most popular algorithm is HNSW (Hierarchical Navigable Small World).
- Think of it like a system of highways and local roads.
- The search starts at the top level ("highway"), where only a few points exist to quickly get to the right "area" of the data space.
- Once the search is close to the destination, it switches to the lower levels ("local roads") to find the exact neighbor.
- This way, the database does not have to check millions of entries, but perhaps only a few hundred jumps.
3. vector database vs. classic database (RDBMS)
The main difference lies in the type of question you can ask.
| Feature | Classic database (SQL/Relational) | Vector database (e.g. Pinecone, Milvus, Weaviate) |
|---|---|---|
| Data structure | Tables (rows & columns), fixed schemas. | Vectors (arrays of numbers) + metadata (JSON). |
| Search logic | Exact match (keyword match). WHERE color = 'red' | Semantic similarity (semantic match). "Find things that look like 'red'." |
| Query | "Find the data record with ID 10." | "Find the 5 data records that are most similar to this image/text." |
| Flexibility | Fails with typos or synonyms (if you search for "car", you will not find "PKW"). | Understands synonyms and context ("car" and "PKW" are close to each other in the vector space). |
| Data types | Text, numbers, structured data. | Unstructured data: Images, audio, long text, video. |
| Languages | It is not possible to find German content with questions in English. | Search for "mountain", "montagne" or "monte" to find German pages about mountains, as the meaning of the word is the same in all languages |
Practical examples
Imagine you are searching a product database for "something to stay warm in winter".
- Classic DB: Finds nothing unless a product contains exactly these words in the description.
- Vector database: The vector for "stay warm in winter" is close to the vectors for "down jacket", "woolly hat" and "fan heater". You receive these products as results, even though the search terms do not appear in the product description.
All content is saved in German, but a visitor only speaks English.
- Classic search: Will not return any results
- Vector database with AI support will both understand the question, find the content and answer in the language of the question.
Summary
A vector database is basically a geometric search engine. It translates meaning into coordinates. The retrieval process is a navigation through this coordinate space using intelligent shortcuts (ANN) to find content that is contextually relevant instead of just looking for exact word matches.
Would you like to know how to set up such a database with Python (e.g. for your own chatbot)?